Minimax algorithm
게임의 진행 상태를 트리에서 정의할 수 있다. 현재 상태를 트리의 루트로 정의하자. 그리고 현재 상태에서 가능한 모든 행동을 해당 노드의 자식 노드로 정의할 수 있다. 만약 게임이 끝난다면 자식 노드는 존재하지 않는다. 아래는 틱택토 게임에서 3수 앞을 트리로 표현한 것이다. 내 말은 O, 상대의 말은 X이고, 내가 행동할 차례면 검은색 원으로, 상대가 행동할 차례면 회색 원으로 표시하였다.
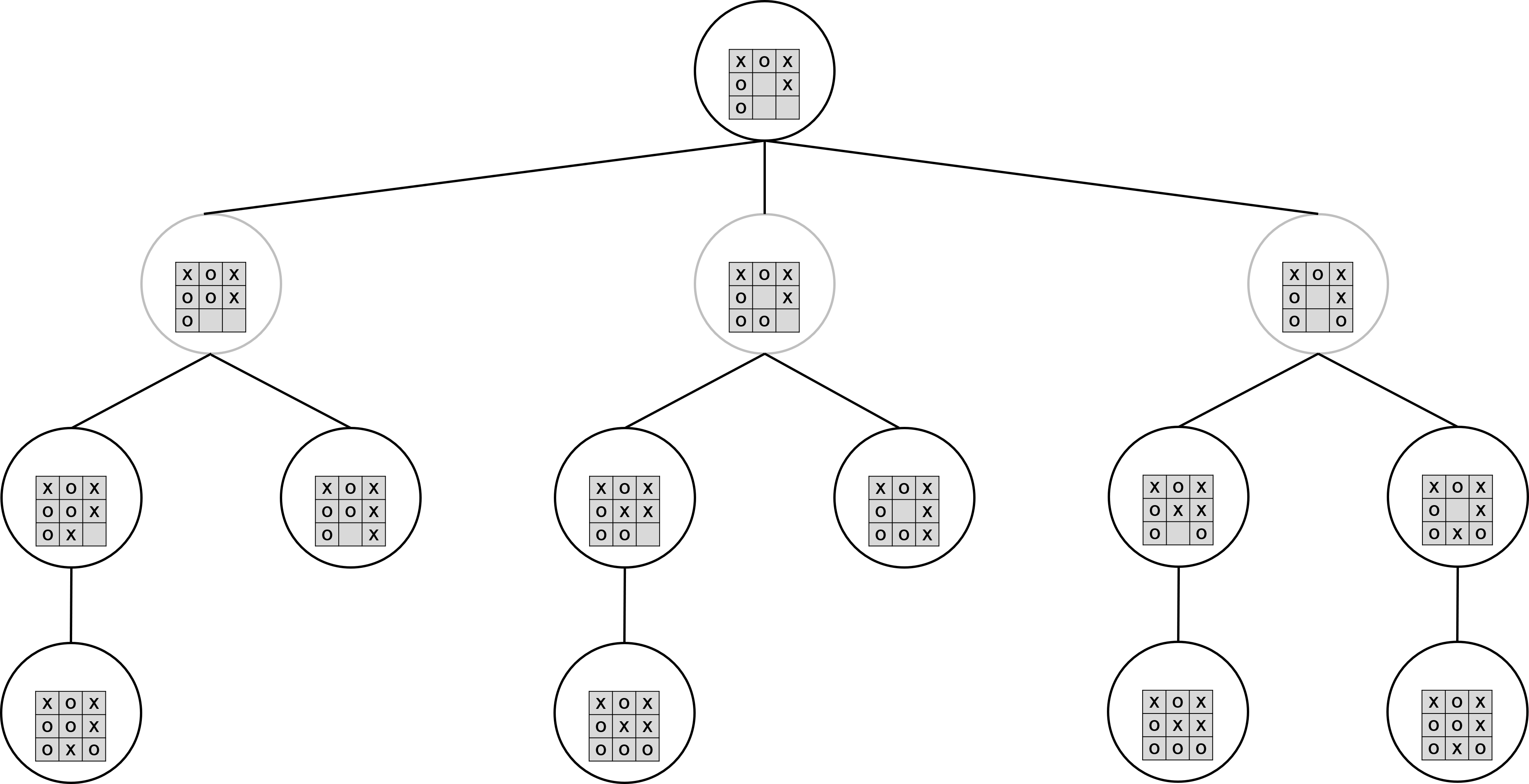
위 트리에서 각 상태의 가치를 평가할 수 있다. 먼저 게임이 끝난 경우에는 가치를 쉽게 판단할 수 있다. 내가 이겼으면 1, 상대가 이겼으면 -1, 비겼으면 0으로 평가할 수 있다. 또한 행동할 수 있는 경우가 하나밖에 없다면, 다음 상태와 현재 상태의 가치는 똑같다고 할 수 있다. 따라서 아래 그림과 같이 노드의 가치를 매길 수 있다.
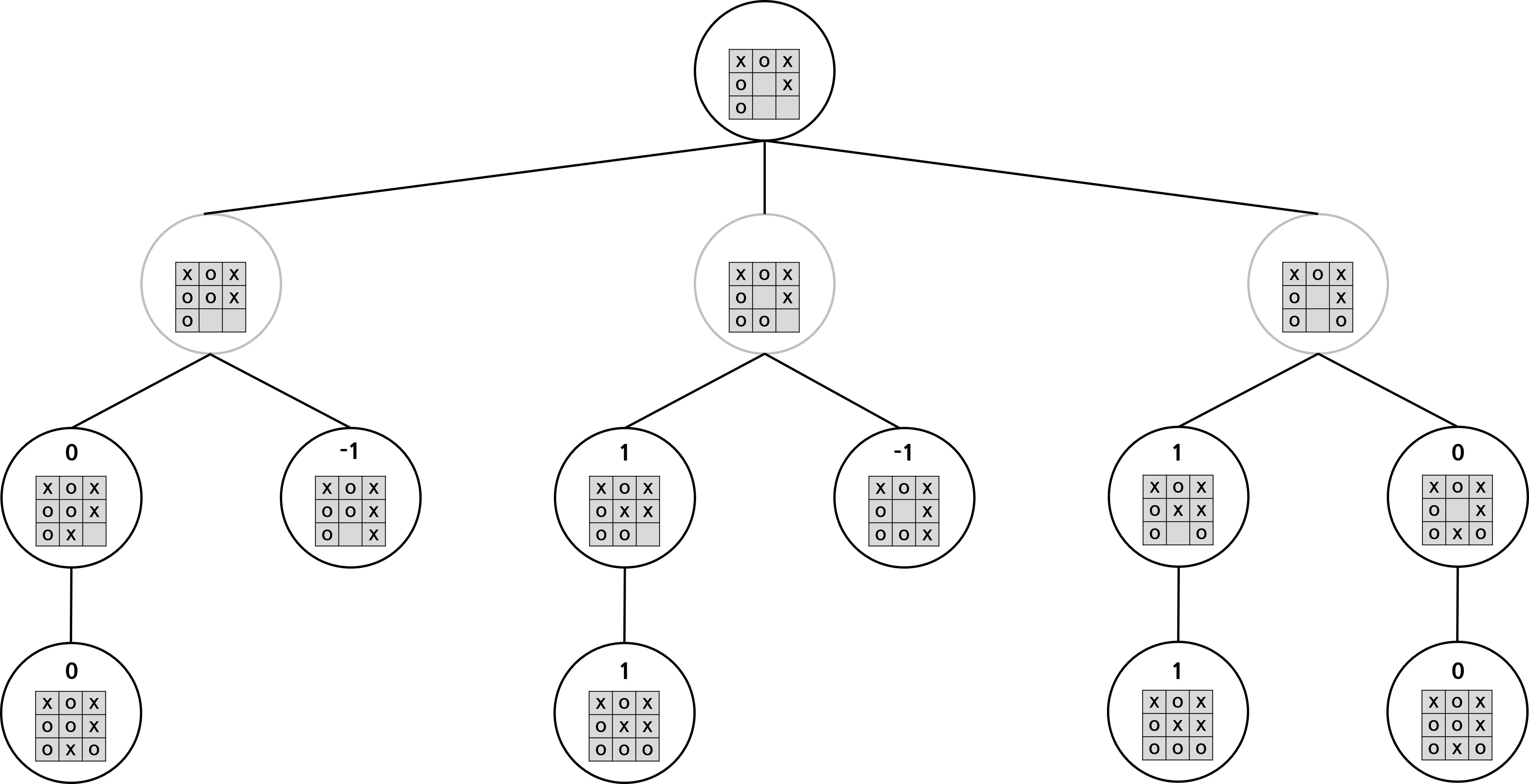
이제 남은 노드들의 가치를 평가해보자. 먼저 회색 노드, 즉 상대 입장에서의 가치를 생각해보자. 상대 입장에서는 가치 점수가 최소가 되는 상태로 이동하고자 할 것이다. 따라서 회색 노드의 자식 노드 가치 중 가장 작은 가치가 회색 노드의 가치가 된다. 내 입장에서는 가치가 최대가 되는 상태로 이동하고자 할 것이다. 따라서 검은색 노드의 자식 노드 가치 중 가장 작은 가치가 검은색 노드의 가치가 된다. 따라서 모든 노드의 가치는 아래와 같다. 빨간색 간선은 나와 상대가 모두 최선의 선택을 할 때 게임이 어떻게 진행될지를 표현한 것이다.
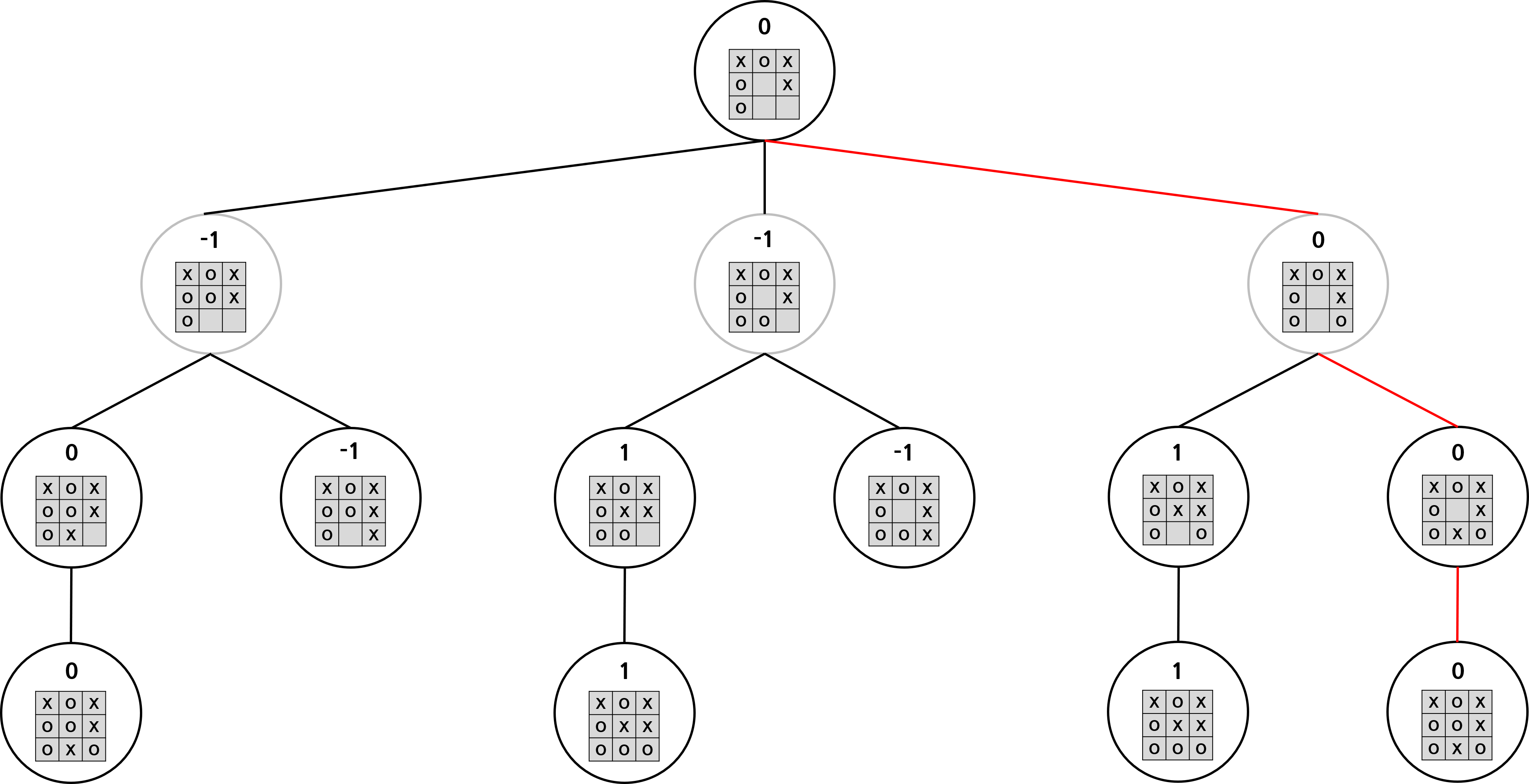
이처럼 트리를 만들어 나와 상대방의 최적의 수를 계산할 수 있다. 나는 항상 가치가 max인 자식 노드를 선택하고, 상대방은 항상 가치가 min인 자식 노드를 선택하므로 minimax algorithm이라 불린다. 이처럼 minimax algorithm은 최적의 답을 찾을 수 있지만, 모든 상태를 봐야 한다는 치명적인 단점이 존재한다.
틱택토에서 가능한 상태의 수는 3의 9승, 약 2만 개로 많지 않은 편이다. 따라서 모든 상태를 트리로 만든 뒤 가장 최적의 상태를 찾을 수 있다. 하지만 4목 게임의 경우 가능한 상태의 수는 약 3^42으로, 중간이 뚫려있는 불가능한 상태를 제외하더라도 상태의 수는 너무 많아진다. 따라서 일반적으로 모든 상태를 고려하는 것은 불가능에 가깝다. Minimax algorithm을 활용하여 최선의 답 대신 차선의 답이라도 얻기 위해 트리를 일정 깊이까지만 구성하고, 일정 깊이 이상에서는 휴리스틱으로 계산한 값을 가치로 대신하는 방법을 사용한다. 예를 들어 4목에서는 (내 3목의 개수) - (상대의 3목의 개수)로 계산할 수 있다.
Alpha-beta pruning
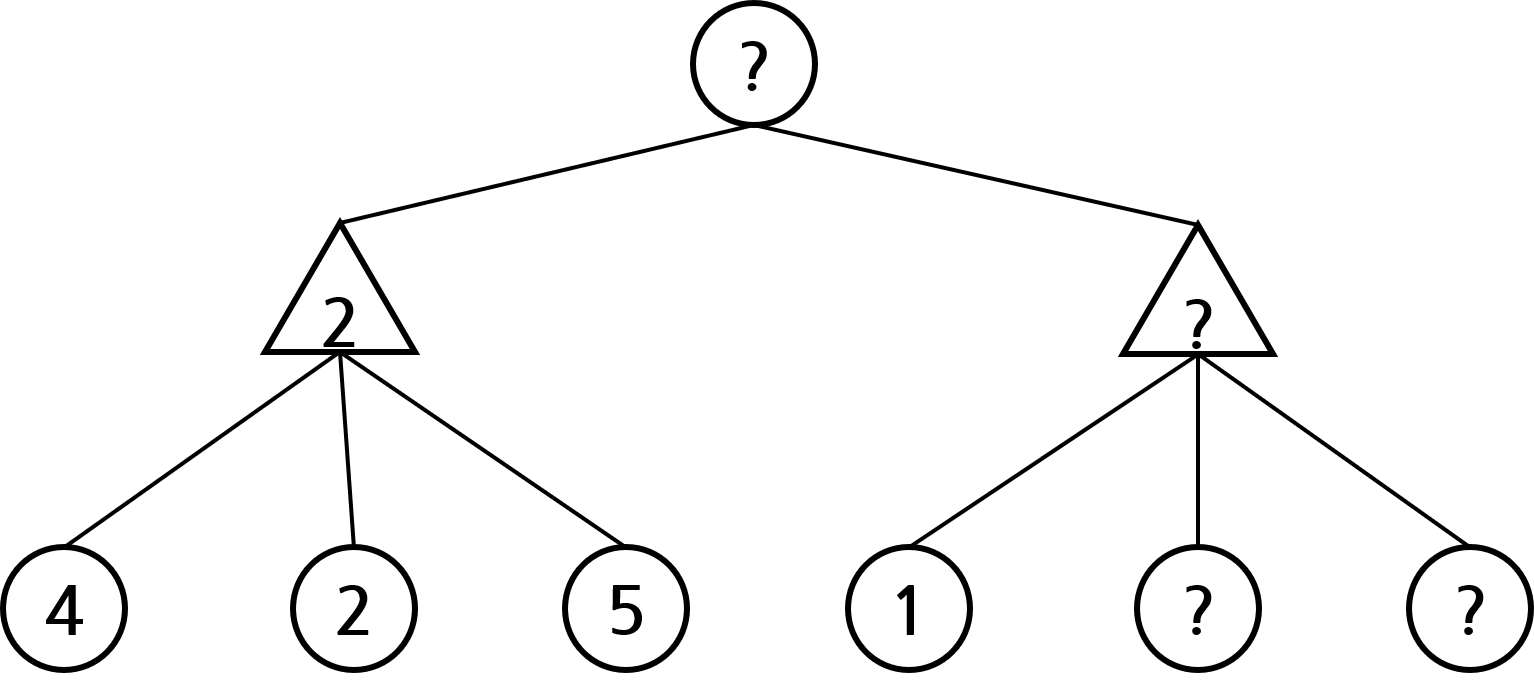
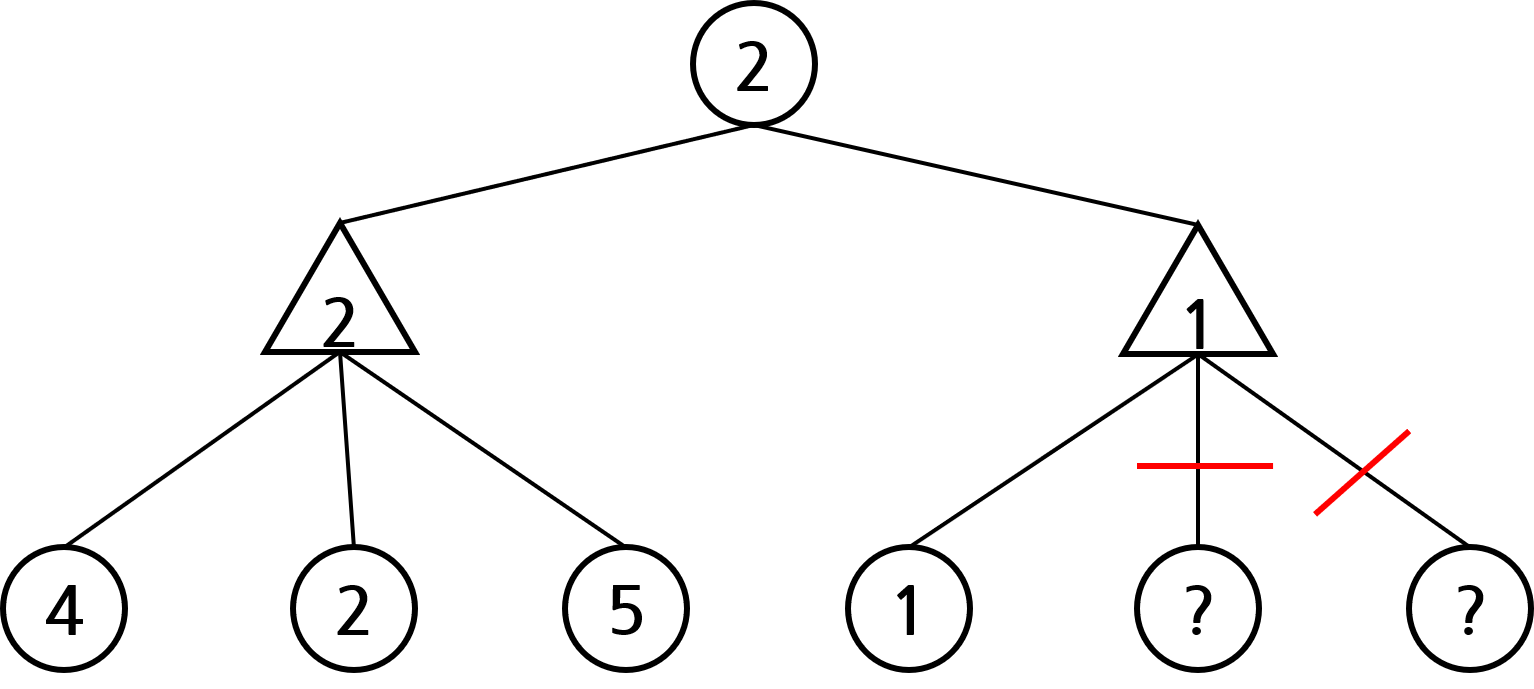
먼저 아래와 같은 상황을 생각해보자. 원은 내 차례, 삼각형은 상대방의 차례임을 의미한다. 각 노드 안의 숫자는 해당 노드 상태의 가치를 의미하고, 가치가 물음표라는 건 아직 확정되지 않았음을 의미한다. 하지만 아래 상황에서 잘 생각해보면 루트 노드의 가치가 2라는 것을 예측할 수 있다.
먼저 오른쪽 삼각형의 가치는 범위가 얼마인지 계산해보자. 일단 오른쪽 삼각형의 자식 노드 중 하나의 가치가 1이기 때문에, 오른쪽 삼각형의 가치는 최대 1이란 것을 알 수 있다. 오른쪽 삼각형 노드의 다른 자식 노드의 가치가 1보다 크면, 상대방은 가치가 1인 노드로 이동할 것이기 때문이다.
그렇다면 루트 노드 기준에서는 무조건 왼쪽 노드를 선택하게 된다. 왼쪽 삼각형의 가치는 2인데, 오른쪽 삼각형의 가치는 최대 1이라 왼쪽 삼각형의 가치가 무조건 더 크기 때문이다. 이처럼 모든 노드의 값을 확인하지 않았음에도, 왼쪽 노드의 가치가 더 높다는 것을 확인할 수 있다.
삼각형 노드의 모든 원 모양 조상 노드 가치 중 최댓값을 \( \alpha \)라 하자. 그렇다면 삼각형 노드의 현재 가치가 alpha보다 작으면 삼각형 노드의 나머지 자식 노드를 확인할 필요가 없다. 위의 예시와 똑같은 논리를 적용하면 된다. 삼각형 노드의 현재 가치가 \( alpha \) 보다 작으면 나머지 자식 노드를 모두 확인해도 삼각형 노드의 현재 가치는 \( alpha\) 보다 커질 수 없다. 따라서 삼각형 노드의 부모 노드는 절대로 삼각형 노드를 확인하지 않기 때문이다. 이렇게 확인할 필요가 없는 노드는 트리에서 잘라내도 된다. 잘라내도 되는 노드는 아래 그림에서 빨간색으로 표시된다. \( \alpha \) 값에 따라 가지를 치기 때문에 이를 \( \alpha-cut\)이라 한다.
\( \beta-cut\)도 \(\alpha-cut\)과 동일하다. 차이점은 기준이 상대 턴이 아니라 내 턴일 때 자른다는 것이다. 아래 그림을 보면, 오른쪽 원의 가치는 7 이상이다. 다른 삼각형의 가치가 얼마이든 이미 가치가 7인 자식 노드가 존재하여 최소 7의 가치인 상태로 이동할 수 있기 때문이다. 루트 노드 기준으로 상대는 왼쪽 원의 가치가 5라는 것을 알고 있고, 오른쪽 원의 가치는 최소 7이라는 것을 알 수 있다. 따라서 상대는 무조건 왼쪽 원을 선택하게 된다. 원 노드의 모든 삼각형 조상 노드 가치의 최솟값을 \(\beta\)라고 하자. 그렇다면 이 원 노드의 가치가 \(\beta\) 보다 커지면 나머지 노드는 가지를 쳐서 확인하지 않는다. 이 경우는 \(\beta\) 값에 따라 가지를 치기 때문에 \(\beta-cut\)이라 한다.

\(\alpha\)와 \(\beta\)의 값에 따라 가지를 치기 때문에 alpha-beta pruning algorithm이라 불린다. 언뜻 보면 minimax-algorithm과 alpha-beta pruning algorithm이 큰 차이가 있나 싶지만, alpha-beta pruning을 포카전 AI전 등에서 활용하면 비슷한 시간에 depth를 1~2 정도 더 탐색할 수 있어, 생각보다 큰 차이가 난다.
Alpha-beta pruning 구현
alpha_beta_pruning.py 파일을 만든 뒤 그 안에 alpha-beta pruning 알고리즘을 구현하였다. 그 후, agent.py에 alpha-beta pruning 에이전트를 추가한 뒤, 에이전트는 alpha_beta_pruning에 정의된 알고리즘을 사용하여 수행할 행동을 계산하는 방식으로 구현하였다. 휴리스틱은 이전의 그리디 알고리즘과 동일한 아이디어를 사용하여 계산하였다. 그 외에도 아래의 추가적인 아이디어를 추가하였다.
이전의 그리디 알고리즘은 상태를 numpy array로 저장하였다. numpy array를 사용해도 실행 시간이 워낙 빨라 고려할 필요가 없었기 때문이다 .하지만 alpha-beta pruning에서는 depth를 하나라도 더 보기 위해서는 빠른 실행 시간이 필수적이다. 따라서 numpy array 대신 int형 변수 2개를 사용하여 상태를 표현하였다. 첫 번째 int변수는 내 말의 존재 여부, 두 번째 int변수에는 상대 말의 존재 여부를 저장하였다. i번째 칸에 말이 존재한다면 i번째 bit를 1로 저장하여 두 int 변수에 판의 상태를 저장할 수 있다. 기존의 42개의 변수 대신 2개의 변수로 맵을 표현하고, 점수 확인도 AND, OR 등의 연산으로 모두 처리할 수 있으므로 훨씬 빠르게 연산할 수 있다.
게임의 초중반에는 같은 시간이 작은 depth만 볼 수 있지만, 게임 후반에는 가능한 action의 수가 줄어들어 상대적으로 많은 depth를 볼 수 있다. 당연하게 많은 depth를 볼수록 더 좋은 행동을 할 확률이 높다. 따라서 depth를 고정하지 않고, depth를 1부터 순차적으로 늘려가다가 행동의 제한 시간이 초과될 것 같으면 함수를 중단해 가장 최근에 얻은 결과를 반환하도록 구현하면 주어진 시간을 최대한으로 활용할 수 있다.
alpha-beta pruning의 구현은 wikipedia의 pseudo code를 참고하였다. 위의 최적화를 추가로 반영한 결과, greedy 에이전트 상대로 약 80%의 승률과 5%의 무승부라는 결과를 내게 되었다.
'AI > 4목 게임 (connect 4)' 카테고리의 다른 글
| [4목 게임 인공지능 제작] 1. 기본적인 그리디 알고리즘 구현 (0) | 2022.08.09 |
|---|---|
| [4목 게임 인공지능 제작] 0. AI 학습을 위한 환경 제작 (0) | 2022.08.09 |